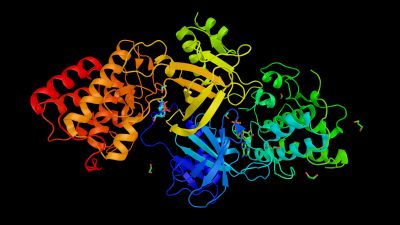
„Bioinformatika je budoucnost,“ shoduje se Marian Novotný a David Hoksza, garanti studijního oboru Bioinformatika na UK. Na výuce spolupracují se zahraničními výzkumnými institucemi EMBL a Max Planck Institute a tím tak studentům a studentkám otevírají dveře do světa už během magisterského studia. Daří se jim i výzkumně – jejich softwarové nástroje využívá i známá proteinová databáze PDBe.

Bioinformatici Marian Novotný (vlevo) a David Hoksza.
„Studijní program bioinformatika je na Univerzitě Karlově poměrně unikátní, protože poprvé se na výuce rovnocenně podílí dvě fakulty. Z našeho pohledu je to jediná cesta do budoucna, protože věda se stává čím dál více interdisciplinární,“ říká bioinformatik Marian Novotný z Přírodovědecké fakulty UK, který o výuce bioinformatiky začal přemýšlel hned po svém návratu ze zahraničí v roce 2008.
„Záhy jsme zjistili, že ,přírodověda´ takový program není schopna sama garantovat, proto jsem oslovil kolegy z Matfyzu,“ dodává. „Ukázalo se, že je to skvělá myšlenka, kterou podporují obě fakulty, ale nikdo nevěděl, jak to skutečně realizovat, protože české zákony nepočítají s tím, že by jeden studijní program garantovalo více fakult. Takže nakonec je přírodovědecká fakulta formálně garantem, ale na výuce se obě fakulty se podílí rovnoměrně,“ upřesňuje David Hoksza z Matematicko-fyzikální fakulty UK. Se smíchem dodává, že studenty si otestují hned na začátku: „Uchazeči si přihlášku podávají na Přírodovědu, ale přijímačky dělají na Matfyzu, což může být matoucí.“ Je to z toho důvodu, že přijímací zkoušky na Matfyz testují především studijní předpoklady a matematický způsob myšlení, což je podle vědců pro úspěšné zvládnutí studia bioinformatiky důležitější. „Algoritmický způsob myšlení se na rozdíl od znalostí biologie jen tak nedoučíte. A také chceme studentům hned od začátku naznačit, že ta část matematiky bude během studia významná,“ dodává Hoksza.

Studenti a studentky Bioinformatiky. Archivní foto z roku 2018.
Praha – Heidelberg – Drážďany
Podle Novotného ani zmatení na začátku není překážkou a o studium je zájem: „Na bakaláře se hlásí kolem šedesáti až osmdesáti zájemců a ke studiu skutečně nastoupí zhruba polovina. Na magistra je to ještě o něco méně – loni jich nastoupilo dvacet. Ale ti, co se pro obor rozhodnou ho i většinou dokončí, nemáme moc studentů, kteří by skončili v průběhu studia.“ Studijní obor Bioinformatika je unikátní i v jiném směru. „Na Matfyzu hned na první pohled poznáte, že na chodbě čeká skupina Bioinformatika. Více jak polovinu studujících tvoří studentky,“ sdílí Hoksza.
Studenti a studentky během bakalářského studia získají základy z informatiky a biologie, na kterých v magisterském studiu budují specifické bioinformatické dovednosti. „Do výuky se snažíme zapojit i zahraniční instituce. Na výuce spolupracujeme s výzkumným centrem EMBL v Heidelbergu a s Max Planck Institute v Drážďanech. Jednáme i o tom, aby tam studenti mohli dělat diplomové práce. Bylo to již domluvené, ale kvůli covidu z toho nakonec sešlo. Nicméně věříme, že se to brzy zrealizuje. Chceme studentům otevírat dveře do světa už během magisterského studia,“ sdílí bioinformatik Novotný, který doktorát získal na Uppsalské univerzitě ve Švédsku a působil také na Evropském Bioinformatickém Institutu (EMBL-EBI) v Hinxtonu jako Marie Curie Fellow.
Jak nová je bioinformatika?
„Slovo bioinformatika se poprvé objevilo v roce 1987 v odborném článku ve francouzštině – použil ho korejský vědec Hwa A. Lim pracující na projektu lidský genom. Významově ale bioinformatika existuje již mnohem déle – první algoritmy pro porovnávání sekvencí a první databáze jsou již ze 70. let,“ líčí Novotný.
Definic bioinformatiky je mnoho. Obecně se jedná o zpracování biologických dat za použití výpočetní techniky. „Jedna část, kterou bioinformatika řeší, je vytěžování dat – jak zpracovat obrovské množství dat a získat informace, které jsou dále využitelné. Druhý směr bioinformatiky je, jak data vytvářet a jak je organizovat – jak získat data z přístrojů nebo jak z nich vytvářet databáze pro další využití,“ popisuje Hoksza. Obrovský nárůst biologických, především sekvenačních dat v posledních letech vyžaduje specifické znalosti a dovednosti: „Člověk musí velmi dobře rozumět biologickým datům – jaké mají limitace a zároveň musí být schopen napsat programy a vědět, jak pracovat s daty. To přesně splňují bioinformatici,“ dodává Novotný.
Od začátku u kormidla
„Biologických dat je stále více. V blízké době nás čeká éra většího využívání strojového učení – zatím jsme na začátku,“ shodují se vědci. Bioinformatika bude nedílnou součástí biologie. „I když do značné míry už je – řada projektů dnes již vyžaduje, aby ‘na palubě’ byl i bioinformatik – někdo, kdo je schopný pracovat s daty – ale často nastupuje až do rozjeté lodě. Myslím, že do budoucna bude ‘u kormidla’ už od začátku,“ přirovnává Novotný blízkou budoucnost, kdy bioinformaci budou s biology hned od začátku diskutovat, kolik, jak a jaká data musí získat, aby se dostali ke kýženým výsledkům.
Prankweb: důkaz místo slibů
 Spojení přírodovědecké fakulty a Matfyzu má i konkrétní výsledky – například softwarový nástroj P2Rank, který umí na povrchu proteinu najít místa, kam se s vysokou pravděpodobností vážou malé molekuly – ligandy. Software, který využívá i známá evropská proteinová databáze PDBe (Protein Data Bank Europe), je založen na strojovém učení. „Software se z dostupných dat v databázích naučil, jak vypadá aktivní místo, kam se váže ligand a naopak, jak vypadají místa, kam se ligandy nevážou. Tyto informace si uloží do modelu a podle něho se pak rozhoduje pro nové proteiny,“ popisuje Hoksza P2Rank, který se takto podle strukturních a fyzikálně-chemických charakteristik rozhoduje pro každý bod na povrchu proteinu. A biologové to ještě vylepšili: „Navíc se díváme na to, jak je konkrétní místo konzervované z hlediska evoluce. Pokud je konzervované, je větší šance, že je důležité a tuto informaci využíváme pro další filtraci a hledání těch opravdu důležitých míst,“ doplňuje biolog Novotný.
Spojení přírodovědecké fakulty a Matfyzu má i konkrétní výsledky – například softwarový nástroj P2Rank, který umí na povrchu proteinu najít místa, kam se s vysokou pravděpodobností vážou malé molekuly – ligandy. Software, který využívá i známá evropská proteinová databáze PDBe (Protein Data Bank Europe), je založen na strojovém učení. „Software se z dostupných dat v databázích naučil, jak vypadá aktivní místo, kam se váže ligand a naopak, jak vypadají místa, kam se ligandy nevážou. Tyto informace si uloží do modelu a podle něho se pak rozhoduje pro nové proteiny,“ popisuje Hoksza P2Rank, který se takto podle strukturních a fyzikálně-chemických charakteristik rozhoduje pro každý bod na povrchu proteinu. A biologové to ještě vylepšili: „Navíc se díváme na to, jak je konkrétní místo konzervované z hlediska evoluce. Pokud je konzervované, je větší šance, že je důležité a tuto informaci využíváme pro další filtraci a hledání těch opravdu důležitých míst,“ doplňuje biolog Novotný.
Software je volně k dispozici přímo online na webu nebo jako samostatná aplikace, která je určena náročnějším uživatelům. „Předností Prankwebu je, že poskytuje výrazně kvalitnější predikce než ostatní volně přístupné nástroje podobného typu. Navíc je snadno použitelný – nemusíte mít žádné předchozí zkušenosti – stačí zadat cílový protein a za několik okamžiků vidíte predikovaná aktivní místa přímo na zadané struktuře,“ shrnují bioinformatici hlavní výhody. Pokročilí uživatelé mohou po stažení aplikace využívat i další funkce, například dělat predikce i na celém proteomu daného organismu: „To jiné nástroje neumožňují – neumí dělat obě varianty – predikovat na široké škále struktur celého proteomu i na konkrétní struktuře jednoho proteinu,“ dodávají.
A o P2Rank je zájem, využívají ho akademické týmy z celého světa. V poslední době byl například využit v několika studiích zaměřených na výzkum nového typu koronaviru SARS-CoV-2 a vývoj léku na covid-19. Pomáhá ale i při hledání ligand-vazebných míst u dalších onemocnění – mapoval třeba možné cíle v bakterii Chlamydia trachomatis, která je nejčastější příčinou oslepnutí vlivem infekce. Kromě toho je P2Rank součástí české části evropské infrastruktury ELIXIR, která slouží k udržitelnému a otevřenému poskytování a analýze biologických dat.
„P2Rank vám zatím neřekne, jaký ligand se kam bude vázat – najde vám ale vazebná místa na povrchu konkrétního proteinu, do kterých pak můžete ‘dokovat’ – vázat konkrétní ligandy. Tento předvýběr celý proces výpočetně výrazně usnadní a zrychlí,“ vysvětluje Hoksza. „Další možností je, že nalezená vazebná místa můžete mutovat a sledovat, jak se mění vazba ligandu,“ doplňuje kolega Novotný. Do budoucna se uživatelé mohou těšit na další zlepšování i nové funkce. Aktuálně se vědci z Matfyzu a Přírodovědy zaměřují na predikce dalších interakcí – konkrétně na interakce protein-protein, protein-DNA či protein-RNA.
| Mgr. Marian Novotný, Ph. D. |
| Působí jako bioinformatik na Katedře buněčné biologie na Přírodovědecké fakultě UK. Ve svých výzkumných projektech se mj. věnuje predikcím posttranslačních modifikací, především fosforylacím. „K posttranslačním modifikacím dochází velmi často, ale naše znalosti jsou stále velmi omezené a často nespolehlivé,“ vysvětluje. |
| RNDr. David Hoksza, Ph. D. |
| Jako odborník na vývoj bioinformatických algoritmů působí na Katedře softwarového inženýrství na Matematicko-fyzikální fakultě UK. Kromě projektu P2Rank se věnuje například projektu na vizualizaci sekundárních struktur ribonukleových kyselin nebo integrované vizualizaci sekvenčních a strukturních dat. „Tento nástroj umožňuje zobrazit sekvenační data v kontextu struktury, což je velmi důležité – hned vidíte, v jaké části proteinu se například nachází studovaná mutace, a to vám může poskytnout mnoho informací, protože struktura je blíže k funkci než samotná sekvence,“ dodává. |
| Společně tvoří mezioborovou výzkumnou skupinu CUSBG – Charles University Structural Bioinformatics Group a od roku 2015 garantují bakalářský a magisterský program Bioinformatika, na kterém se rovnocenně podílí PřF a MFF UK. |